
Intro
Zoom backgrounds are just so… cheesy. Reminiscent of some kind of student compositing project from the early 2000’s.
Let’s see if we can do something cooler 🙂
First, what tools do we have available? Unlike in the early 2000’s, where the multimedia software landscape was torn up between a few proprietary players, we now have a nice suite of free, open-source tools, that can be integrated together into complex fully-automated pipelines for example:
- RawTherapee — RAW image processing, great support for batch processing and scripted automation (bash, python, whatever you want really). My preferred tool for RAW processing.
- Krita — Digital painting, illustrating, animating. Great to use with a Wacom tablet.
- Blender — 3D + 2D full workflow in one package. Perhaps a little weak in some areas (e.g. compositing, simulation), but still incredibly powerful over-all.
- Inkscape — Lacking compared to Illustrator but it’s fine for most vector art work I’ve had.
- GIMP — Probably a decent free Photoshop alternative if you’re not a power-user of Photoshop, but the interface is horrible and I can’t stand using it for more than very quick edits.
Objective
What do choose? Well, that depends on what we want to do. We could do some augmented reality, injecting CGI stuff into the webcam stream… But children already do that with smartphone apps nowadays.
Initial ideas:
- Extract head from video (face detection + grabcut extraction?), and have the head bouncing around the viewport like a DVD logo?
- Preserve foreground while applying style transfer to the background?
Let’s make challenging… How about taking some inspiration from Black Mirror:
- Facial shapekeying with Blender to make a real-time “deepfake”?
Ok, the challenge is to develop a filter which will map my facial expressions (from a webcam stream) onto some 3D CGI model in real-time, and push that into a mock webcam stream that other programs (e.g. Zoom, Jitsi) can then use.
Modelling the data flow
Since we want to render a 3D scene, we’ll use Blender for the CGI generation. The pipeline is probably going to be something like this:
Frame from webcam stream → detect faces → identify "main face" → → detect facial expression → analyse facial expression → → send expression data to Blender → blender render → → write frame to fake webcam stream → → other programs can read that as if it was a real webcam
While Blender has a “real-time renderer” (Eevee), the term “real-time” can have different meanings in different contexts. In my case, I need Blender to be able to render a frame for me within 50ms of me requesting it, so that the latency of the fake webcam stream is not too high. I suspect that when Blender devs say “real-time”, they mean “you don’t have to wait overnight for it to render” rather than the “hard real-time” which I’m looking for here. But we play the cards we’re dealt, let’s see what the best we can achieve with Blender is.
We’ll use Linux for this, although the resulting project could be ported fairly easily to other platforms. The only platform-dependent part should be the video/webcam API.
After figuring out what responsibilities go to what software components, our data flow becomes something like this:
Linux kernel · Our program · Blender
v4l2 ØMQ
· ·
Webcam ▶ analyse frame, extract face info ▶ receive info
· · ▼
· · render frame
· · ▼
Loopback sink ◀ final post-processing/conversion ◀ send frame
▼
Loopback source
◢
Other programs e.g. Zoom, Chrome
We want to have less than 100ms from frames being read from the webcam to them being pushed into the loopback sink, otherwise audio will fall too far out of sync and the face movement in the resulting video will just look random instead of being coördinated with speech.
Dependencies
We will use the following 3rd-party stuff:
- Blender, for the CGI rendering
- v4l2 kernel interface for video streams.
- v4l2loopback kernel module for fake webcam.
- OpenCV library for image processing.
- dlib for face detection and feature extraction, as it runs fine on CPU and my laptop uses an ancient GPU with very limited compute capabilities.
- pipeline++ library for building a multi-threaded pipeline.
- ZeroMQ sockets library for connecting our program to Blender.
Since we want consistently low latency and hassle-free multi-threading, I’ll use C++ for this rather than e.g. Python. This also gives me some opportunity to experiment with image data representation and colour spaces, as a learning activity. In theory, the threaded stages of the pipeline could be mirrored in Python using pathos.multiprocessing, but we’d still have latency spikes and far lower throughput for computations done within our own code.
Modelling the pipeline
Thanks to the nice syntactic sugar available from the pipeline++ library, our pipeline literally looks like this in the source code:
load_image >> find_faces >> map_features >> normalise_face >> blender_face >> fps_monitor >> save_image;
Let’s go through the stages:
- load_image — Read an image from the input. The input is injected as a producer functor, so the actual input could be a test file, ffmpeg pipe into standard input, or a V4L2 video source.
- find_faces — Shrink the image temporarily then apply dlib’s “frontal_face_detector” to find locations of faces. Based on positions of the main face in previous frames, we also apply a little extra optimisation by cropping the source image around where the face previously was located in the frame. Contrary to the typical engineer’s “common sense”, reducing the size of a large image can actually improve the accuracy and precision of some feature detectors/analysers.
- map_features — within the bounding box for the detected face, run dlib’s extremely fast feature detector, to detect position and orientation of nose, mouth, chin, ears, eyebrows, etc.
- normalise_face — apply affine transformation to face such that some feature points (sides of head, top of nose) are transformed to the same location for each frame. This allows us to mostly cancel out the position/orientation of the head, since we only care about facial features e.g. the movement of lips, eyelids, eyebrows, etc; not the movement of the head itself.
- blender_face — render the CGI image with blender.
- fps_monitor — write timing data and frame rate to STDERR.
- save_image — write the final image to an output. The output is injected as a consumer functor, so could be a test file, ffplay pipe from standard output, or a V4L2 video sink.
While prototyping, I spent some time exploring the YUV family of colour spaces.
I developed other pipeline components while exploring what was possible with dlib+OpenCV, including some labelling/annotating stages while debugging.
Preview #1: face feature detection and labelling/segmentation
Preview #2: face normalisation (top-right of monitor window)
The Blender part
Blender has a Python scripting API which is nice, and a little IDE in the Blender UI itself for developing/testing scripts. We can then invoke the script headlessly as part of a script for production use.
The inevitable ZeroMQ mini-pitch
I pretty much can’t use ZeroMQ in a project without also promoting it in the write-up. In order to avoid having to think at all about how we communicate between the C++ program and the Blender program, we will use ZeroMQ. ZeroMQ provides strict communications patterns (e.g. request/reply, publish/subscribe, push/pull), and is easily (re-)configurable for communicating between:
- threads in the same program without sharing any mutable state in your own code, via in-process queues
- processes in the same environment, via UNIX sockets,
- machines over physical networks, via TCP/IP sockets.
It’s an extremely versatile networking library, I recommend getting familiar with it. It is especially useful when you have several components written in different programming languages and you need to connect them. Although for higher-level and more complex systems, gRPC is probably a better fit than ZeroMQ.
Most of what it does for me out of the box, I’ve implemented by myself in the past projects, and it really just is not worth the time / effort / risk to do that if ZeroMQ is available.
Back to Blender
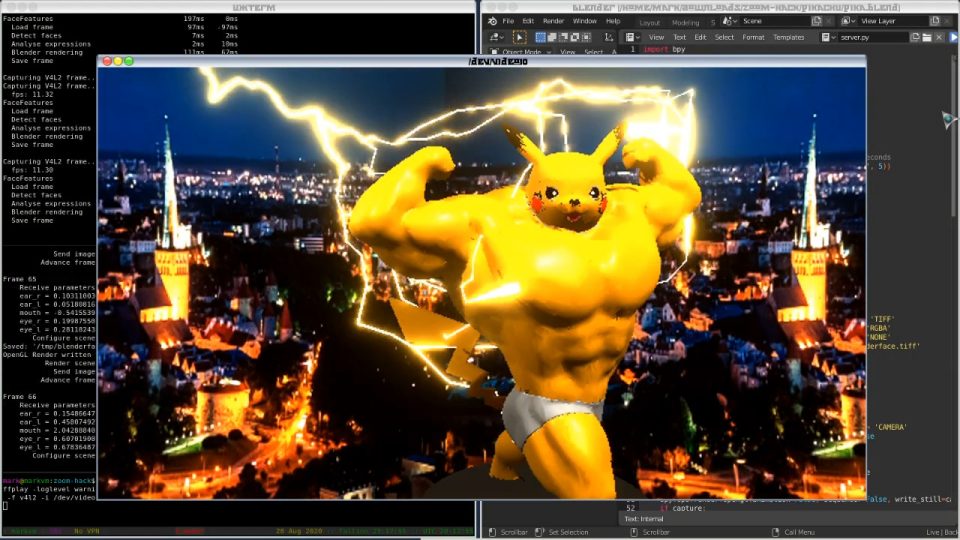
I found a suitable model on Thingiverse that I would like to transfer my expressions onto. With hindsight, I should have taken a model with larger facial features, as the movements on this model were difficult to see.
After some UV-unwrapping and vertex painting, I had a pretty nice looking model. Load in a city skyline background photo and the scene looked quite nice. I felt that the scene still looked a bit empty though so I added some lightning, configured to crawl over my avatar’s skin in a dramatic fashion.
{kind=link}
I added shape keys to the model, so I could easily control changes in facial expressions.
With the modelling done delegated, painting done, and animation complete, shapekeying done, the remaining step is to integrate the Blender rendering into my video pipeline, using Blender’s scripting interface and ZeroMQ. The blender scripting part was pretty simple – the online reference is quite complete, and the UI is helpful in showing me the underlying python commands for UI interactions.
So I ran the pipeline….. and waited… Ah crap, the blender file is configured to use the Cycles renderer. I switched it back to the Eevee real-time renderer and re-ran. I started getting frames back from blender, but the frame rate was horrible. Maybe one frame every two seconds. I reduced all quality settings in Blender as far as possible, and the render image size, but the latency was still terrible.
Getting real-time on-demand renders from Blender
Some lessons learned, from trying to get low latency rendering:
- The output render format matters (obviously). Emitting compressed PNG will incur huge latencies due to zlib compression, while uncompressed TIFF is lightning fast to encode.
- Blender has several different render types. This is unrelated to the engine (Eevee/Cycles) or Wire/Solid/Material/Rendered viewport shading types. There is “render render” and “OpenGL render”. The former is used when you hit “render” in Blender, while the latter is used in the interactive viewport. We want to use the “OpenGL render”, as it is much faster (even for an empty scene) than the “render render”.
- Don’t use the sequencer, it’ll add more latency.
- Render a scaled-down image then do a bicubic enlarge, to improve latency further.
- Restricting hooks to the minimum set of vertices (via vertex groups) will give huge performance increases for mesh modifier calculation when hooks are changed between frames, compared to binding each hook to the entire mesh.
Some render-time measurements:
- Blender render (“render render”), cold (i.e. after modifying a hook/shapekey):
bpy.ops.render.render(write_still=…)
800ms - Viewport render (“OpenGL render”), cold:
bpy.ops.render.opengl(animation=False, sequencer=False, write_still=…, view_context=True)
200ms - Viewport render, hot (immediately after a render, no changes in between):
80ms - Viewport render animation
bpy.ops.render.opengl(animation=True)
200ms - Play animation
bpy.ops.screen.animation_play()
70ms
After replacing the shape-keys with hooks, and binding them each to the minimum amount of mesh necessary, the render time of the blender stage was now low enough for practical use in a real-time pipeline.
Preview #3: Real-time facial-expression transfer onto CGI model
Result
See preview #3.
Ok, it wasn’t great, but it’s a good start.
Everything seems to be working as expected.
To improve it, the following should help:
- Better webcam – something capable of 720p @ 24fps or higher, more sharpness and far less noise.
- Better lighting so contrast is stronger and there’s less camera noise.
- Stronger difference between foreground (face) and background.
- Lighter skin-tone test subject, so dlib’s face feature extractor will have more contrast to work with vs my face.
- Re-train face feature extractor with a larger and better-quality pre-labelled dataset.
- Put more artistic thought into the Blender scene, and what model we use, and camera movement animation.
- Noise filtering (lowpass) for facial expression data. Perhaps also combine audio spectral data (for mouth shape) with the video data, via Kalman filter